
What Are Classification Metrics?
June 6th, 2019
So, you have your first interview for your dream data science job. You begin chatting with the interviewer, and ace all of the behavioral questions. What’s your greatest strength? Your greatest weakness? You already know these answers because they’re the same answers you have given in countless other interviews. The interview then takes a shift to the more technical, and you’re asked about regression. You use everything you learned in your statistics courses to answer these questions as well. The interviewer, impressed, then asks “ What is your strategy for selecting appropriate classification metrics?”
Caught off-guard, you think hard, and vaguely recall a time when you heard about these concepts, but are not sure enough to answer the question. You thank the interviewer for their time, and go home hoping that the rest of the interview outweighed the conclusion.
In order to try and help you on your next interview, I’m going to go over the most common classification metrics. To assist with the explanations, I’m going to use examples from an interesting dataset that was provided by the City of Chicago about their ride-shares. The main question we want to answer is, “Will a trip end with a tip?” My colleague, Ryan Harrington, posted an analysis using this dataset last week, so if you want to get some background on it click here.
Overall, these classification metrics provide both a sense of how the classifier is performing, as well as an idea of what to potentially change to improve performance.
Precision
Let’s start with precision. In our example, we are trying to predict whether or not a passenger will tip the driver based on a number of variables. One thing we want to know, is out of all of the passengers who we predicted to tip, what percent actually tipped?
To make calculating these metrics easier, it will be helpful to first construct a confusion matrix. This is a 2x2 table that shows four things:
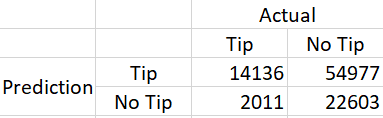
# of true positives: We predicted a passenger to tip, and they did tip (14,136)
# of false positives: We predicted a passenger to tip, but they did not tip (54,977)
# of true negatives: We predicted a passenger to not tip, and they did nottip (22,603)
# of false negatives: We predicted a passenger to not tip, and they did tip (2,011)
To find out how many customers we predicted would tip, we can add the number of true positives, and the number of false positives (since this will add up to the total number of predicted positives — total passengers we predicted will tip). The number of passengers who we correctly predicted would tip is just the true positive number.
We can use the following formula:
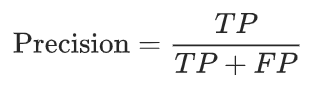
This gives us a percent for the relationship we’re interested in: passengers we correctly predicted to tip, out of all the passengers we predicted to tip. The precision here is 14136/(14136 + 54977) = 0.205. Not good, but usable for this example.
Great! Doesn’t this sound like all we need? Precision sounds like it tells us how good our model is, right? Well…not exactly.
While not the case in this example, the problem we run into is that if our model is very conservative (only predicts a tip if it is very sure), we end up having a “perfect” precision rate of 1, since the model will have 0 false positives. However, we end up having a lot of false negatives, because the conservative model is predicting only a small number of tipping passengers. We want to correctly predict tips and non-tips, so precision is not giving us the best picture of the results.
Recall
Instead of focusing solely on false positives, and positive predictions in general, recall also accounts for the false negatives.
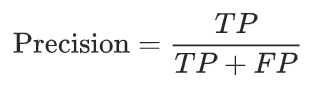
Taking the above example, while precision is .205, recall is 14136/(14136 + 2011) = .875 due to the small number of false negatives in the denominator. With recall, the question is how many passengers do we correctly predict will tip, compared to the total number of passengers who actually tipped. Because this equation looks at all passengers who tipped, it takes into account the passengers who actually tipped, but the classifier predicted did not tip. This is the reason why our recall rate is so high: our classifier is not making many false negatives (not detecting passengers who tip), but is making too many false positives which is reflected in the precision rate.
As shown here, both precision and recall are necessary to determine if your classifier is performing well. High scores in precision and recall are important. Sometimes precision and recall are combined into one measure, called f-measure.
F-Measure
The F-measure (also referred to as the F1-score), is essentially just a way to combine recall and precision to have one score that can be used to see how well your classifier is performing. The calculation is very similar to how an average is calculated:
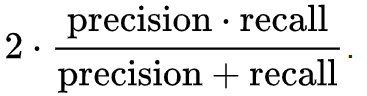
F-measure is calculated by simply taking the product of precision and recall in the numerator, dividing by the sum of precision and recall, and finally multiplying by 2. The F-measure can range from 0 (worst classifier) to 1 (best classifier).
In our case, the F-measure is .332. Clearly, this classifier did not do very well. Maybe it’s just difficult to predict tipping with the available data.
ROC Curve
The Receiver Operating Characteristic (ROC) curve is ubiquitous in classification evaluation. It’s often used because it provides a visual for how the classifier is performing.
First, a couple of definitions:
Sensitivity: This is simply the true positive rate. As sensitivity goes up, our classifier is predicting more people tipping, who actually end up tipping.
Specificity: This is the true negative rate. For example, a specificity of 1 means all passengers who did not tip, were not predicted to tip. Often, the x-axis of an ROC curve uses (1-specificity) instead of specificity which is actually the false positive rate. It makes sense that false positive is the inverse of true negative, since more frequent positive predictions increases your chance of making false positives, and decreases your chance of making true negatives — again because for true negatives you need to make less frequent positive predictions. In this example, I will simply use specificity.
The ROC curve plot is useful because it visually shows you the potential trade-off of your classifier. This type of plot will always have a point at (0 sensitivity, 1 specificity), and (1 sensitivity, 0 specificity). This is because your classifier could always just predict that people will tip, or no one will tip. In either of these cases, it EITHER correctly predicts everyone who would tip ORcorrectly predicts everyone who would not tip. Of course, we want a balanced classifier that is able to predict tipping passengers and non-tipping passengers at the same time.
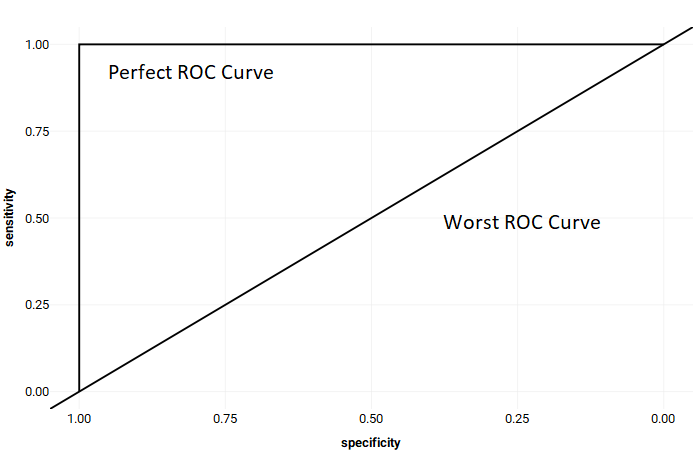
Example of a perfect ROC Curve
As you go up the curve, sensitivity increases and specificity decreases. If a perfect classifier existed, it would be just a right angle, with a straight line from (0 sensitivity, 1 specificity) to (1 sensitivity, 1 specificity). Such a classifier would have predicted everything perfectly. It would have a true positive rate of 1 (correctly predicting every single passenger who tipped), while retaining a true negative rate of 1 as well (correctly predicting every single passenger who did not tip).
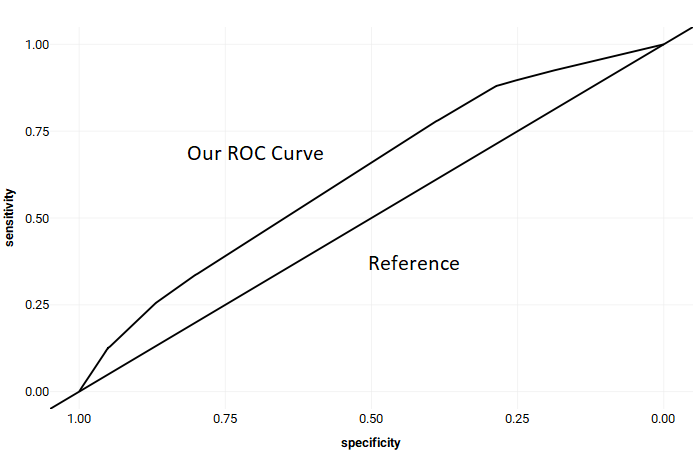
In the case of our example, we see two lines: our ROC curve with a diagonal reference. The reference indicates a classifier that is no better than chance. Since our ROC curve is higher than the diagonal line, it means we are predicting better than chance, but not by much. Each point on the curve represents a trade-off between false negatives and false positives.This is where things can start to depend on the task at hand. The more you go to the right, the less strict your classifier is, meaning you’re going to get more true positives, at the cost of getting more false positives (and less true negatives).
While in our current example of tipping, an argument can be made in either direction for either a less/more strict classifier, if you’re instead screening for chronic illness, then you may have a preference.
For example, if a true positive in a problem is predicting correctly that someone has a disease, then you will probably prefer to keep your model less strict. This is because a false positive (telling someone they’re sick when they’re not), while still not great, is a better alternative than a false negative (telling someone they’re healthy when they’re not). For the false positive, it will be embarrassing and you will end up scaring the patient. However, in the false negative you risk not treating someone who is sick. By making a classifier less strict, you have less false negatives, but more false positives. It depends on the context of the problem what you prefer.
I won’t get into details on the topic in this particular blog post, but classifiers typically have a way to control a certain threshold of how strict they are on predictions. That is where you are able to tweak it to your preference. But the ROC curve is a great tool to see the trade-offs between false positives and false negatives.
AUC
Area-under-the-curve (AUC) is part of the ROC curve above. It’s actually giving you a value of how large the area under the ROC curve is. This is another way of seeing how well your classifier is performing and is typically outputted in the same function that provides the ROC curve.
An AUC of 1 indicates a perfect classifier (i.e. predicting every passenger who would tip, and predicting every passenger who would not tip with no error). This curve would look as I showed earlier: a right angle on the left side of the x-axis. On the other hand, an AUC of 0.5 would be a completely random classifier. It has the same chance of incorrectly predicting someone who would tip as incorrectly predicting someone who would not tip. The closer to 1, the better the classifier. Typically, in real-world problems an AUC between 0.9 to 1 is considered the gold-standard. An AUC of 0.75–0.9 is still very good, while below 0.7 isn’t great.
In this example, the AUC is 0.623. This is a pretty poor AUC, but still better than chance which would be 0.5.
And that’s it for the most common classification metrics! Hopefully, this was helpful. Now go out there and impress those interviewers!